Recently, actually the same day iTunes came out with the podcasting update, I downloaded iPodder as I did not want to be left behind and wanted to see what all the noise was about. Few shows seems to have caught my interest since then. One that did catch my interest was The Chris Pirillo Show. I had never watched The Screen Savers on Tech TV as I was sans digital cable and so the reason the show stuck out was the focus on emergent web technology and the delightful banter between him and Ponzi.
Recently he interviewed Rick Kim from Cyworld which is a web service from Korea that has really taken off and seem to have 90% of Korea in the palm of their hand. Chis is usually a good interviewer because while he is very knowledgeable he does a good job of ‘pretending’ he doesn’t know what his interviewee is talking about to get better explanations out of them (I bet I can hear Ponzi laughing in the background already). This works really well in most situations when he does know what’s going on but when Rick came on Chris seemed to miss the boat of understanding.
Cyworld really is revolutionary in it’s inclusion of elements from other places. Chris blows the service off as some kind of glorified geocities where you have to pay for backgrounds but it reality it is so much more. If I had to define it, after doing some research on it, I would more associate it to SecondLife. SecondLife has a monthly fee like World of Warcraft but you can pay extra money to buy things like land or whatever. While there have been detailed studies of online game economies since Ultima Online every one always seems to be surprised when actual money starts to come in to the picture.
Cyworld is basically a social network. For free you can sign up for an account and you get a little page that includes a personal profile, diary, mini room, photo album, bulletin board and message board. Non of this is out of the ordinary and sounds a lot like MySpace that has (unfortunately) become very popular in the US. What is unique is the mini room where for free you get a small customisable avatar and an empty room. But if you want to decorate the room you have to buy little object with real money. The objects are cheep (under $2) and some even only last a limited amount of time. The object also are part of the social networking as you can buy gifts for others and these gifts end up effecting your friendly or sexy score.
The trick seems to be offering something for free and then making available other stuff to buy. It’s a model cropping up all over the place. iTunes is a free download and does a great job on managing people’s music and now it even lets you manage your podcasts. Oh and if you’re up to it you can purchase music from one of the largest online music stores in the world. Google Earth is a free download with amazing functionality and with a small fee can also be upgraded to even more powerful features. It’s this kind of pseudo-shareware that seems to becoming very pervasive in the online market the way it was with video games in the early 90s.
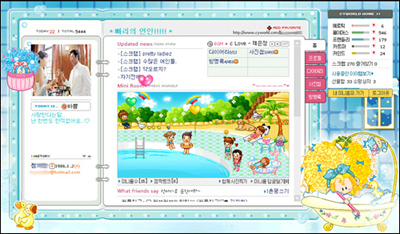
Chris really dropped the ball on this interview and really sounded insulting to Rick. Any company that is making $200,000 a day should be given more respect and understanding. After seeing TheFaceBook sweep through TCNJ and people truly becoming obsessed with it I can easily see Cyworld taking off in the US. Currently I see it’s main competitor to be MySpace in the obsessive social networking sphere. I wish it the best of luck and while I do plan on trying it (I’ll sign up for about any free service) I don’t plan on spending any money since I’m a bit cheep.
Cyworld, MySpace, ChrisPirillo, SocialNetwork, Korea, SecondLife